
Le ministère américain de la Justice a publié plusieurs nouvelles pièces de procès dans le cadre de l’audience de recours en cours. Ces expositions comprennent des interviews avec deux ingénieurs de Google clés – Pandu Nayak et HJ Kim – qui offrent un aperçu des signaux et des systèmes de classement de Google, des fonctionnalités de recherche et de l’avenir de Google.
Terminologie du système de classement Google de recherche Google
Nayak a défini une terminologie clé Google et a expliqué la structure de recherche de Google:
- Document: Ce que Google appelle une page Web ou sa version stockée.
- Signaux: Comment Google classe les documents qui génèrent finalement le SERP (pages de résultats du moteur de recherche). Google a parlé de l’utilisation de signaux prédictifs des modèles d’apprentissage automatique ainsi que des «signaux traditionnels», probablement du sens basé sur des données côté utilisateur (ce que Google a précédemment appelé les interactions utilisateur – par exemple, clics, attention sur un résultat, glisse sur des carrousels, entrant dans une nouvelle requête). D’une manière générale, il existe deux types de signaux de classement:
- Signaux bruts. Ce sont des signaux individuels. Google a «plus de 100 signaux bruts», selon Nayak.
- Signaux de niveau supérieur. Il s’agit d’une combinaison de plusieurs signaux bruts.
Les autres signaux discutés par les ingénieurs comprenaient:
- Q * («Q Star»): Comment Google mesure la qualité du document.
- Navboost: Un signal traditionnel mesurant l’utilisateur clique sur un document pour une requête, segmenté par emplacement et type de périphérique, en utilisant les 13 derniers mois de données.
- Rankembed: Un signal Google principal, formé avec des modèles de langue importants (LLM).
- Pagerank: Un signal Google original, toujours un facteur de qualité de page.
Google utilise également des Twiddlers pour ré-classez les résultats (que nous avons appris à partir de la fuite de l’entrepôt de l’API de contenu interne de Google de l’année dernière). Une «interface de débogage» interne permet aux ingénieurs de voir l’expansion / décomposition des requêtes et les scores de signal individuels qui déterminent le classement final des résultats de la recherche.
Google abandonne des signaux mal performants ou obsolètes.
Navboost: pas un système d’apprentissage automatique
L’ex-Googler Eric Lehman a été demandé si Navboost s’entraîne sur 13 mois de données utilisateur et a témoigné:
- «C’est ma compréhension. Maintenant, le mot« trains »ici pourrait être un peu trompeur. Navboost n’est pas un système d’apprentissage automatique. C’est juste une grande table. Il dit pour… cette requête de recherche, ce document a eu deux clics. Pour cette question, ce document a obtenu trois clics… et ainsi de suite.

Recherche Google: de la tradition à l’apprentissage automatique
La recherche de Google a évolué à partir de la fonction traditionnelle de classement «OKAPI BM25» pour intégrer l’apprentissage automatique, en commençant par RankBrain (annoncé en 2016), puis, plus tard, Deeprank et Rankembed.
Google a constaté que les signaux d’apprentissage automatique Deeprank basés à Bert pouvaient être «décomposés en signaux qui ressemblaient aux signaux traditionnels» et que la combinaison des deux types a amélioré les résultats. Cela a essentiellement créé une approche hybride de la récupération traditionnelle de l’information et de l’apprentissage automatique.
Google «évite simplement« prédire les clics », car ils sont facilement manipulés et ne mesurent pas de manière fiable l’expérience utilisateur.
Randi
Un signal clé, Rankembed, est un «modèle d’encodeur double» qui intègre des requêtes et des documents dans un «espace d’incorporation». Cet espace considère les propriétés sémantiques et autres signaux. La récupération et le classement sont basés sur un «produit DOT» ou une «mesure de distance dans l’espace d’intégration».
Rankembed est «extrêmement rapide» et excelle dans les requêtes courantes, mais lutte avec des requêtes à longue queue moins fréquentes ou spécifiques. Google l’a formé sur un mois de données de recherche.
Topique, qualité et autres signaux
Les documents détaillent comment Google détermine la pertinence d’un document pour une requête, ou «d’actualité». Les composants clés incluent les signaux ABC:
- Ancres (a): Liens d’une page source à une page cible.
- Corps (b): Termes dans le document.
- Clics (c): Combien de temps un utilisateur est resté sur une page liée avant de revenir au SERP.
Ceux-ci se combinent en t * (topique), que Google utilise pour juger la pertinence d’un document pour interroger les termes.
Au-delà de la topique, «Q *» (qualité des pages), ou «fiabilité», est «incroyablement important», en particulier pour aborder les «fermes de contenu». HJ Kim note: «De nos jours, les gens se plaignent toujours de la qualité et l’IA aggrave.» Pagerank alimente le score de qualité.
Les autres signaux incluent:
- EDEPRANK: Un système LLM utilisant Bert et Transformers pour décomposer des signaux basés sur LLM pour une plus grande transparence.
- BR: Un signal de «popularité» utilisant des données chromées.
Signaux fabriqués à la main
Bien que l’apprentissage automatique augmente en importance, de nombreux signaux Google sont toujours «fabriqués à la main» par les ingénieurs. Ils analysent les données, appliquent des fonctions comme les sigmoïdes et définissent les seuils sur les signaux affinés.
«À l’extrême», cela signifie sélectionner manuellement les données à mi-points. Pour la plupart des signaux, Google utilise une analyse de régression sur le contenu de la page Web, les clics des utilisateurs et les étiquettes des évaluateurs humains.
Les signaux fabriqués à la main sont importants pour la transparence et le dépannage facile. Comme l’a expliqué Kim:
- « La raison pour laquelle la grande majorité des signaux sont fabriqués à la main est que si quelque chose se casse, Google sait quoi corriger. Google veut que leurs signaux soient entièrement transparents afin qu’ils puissent les déposer et les améliorer. »
Les systèmes d’apprentissage automatique complexes sont plus difficiles à diagnostiquer et à réparer, a expliqué Kim.
Cela signifie que Google peut répondre aux défis et modifier les signaux, comme les ajuster pour «divers défis d’attention des médias / publics».
Cependant, les ingénieurs notent que «trouver les bords corrects pour ces ajustements est difficile» et ces ajustements «seraient faciles à rétro-ingénieurs et à copier en regardant les données».
Index de recherche et données côté utilisateur
L’indice de recherche de Google est le contenu rampé: titres et corps. Des index distincts existent pour un contenu comme Twitter Feeds et les données de Macy. Les signaux basés sur les requêtes sont généralement calculés au moment de la requête, non stockés dans l’index de recherche, bien que certains puissent être destinés à la commodité.
«Données côté utilisateur», aux ingénieurs de recherche Google, désigne les données d’interaction utilisateur, et non des contenus générés par l’utilisateur comme les liens. Les signaux affectés par les données côté utilisateur varient dans la mesure où ils sont affectés.
Fonctionnalités de recherche
Les fonctionnalités de recherche de Google (par exemple, les panneaux de connaissances) ont chacune leur propre algorithme de classement. «Tangram» (anciennement Tetris) visait à appliquer un principe de recherche unifié à toutes ces fonctionnalités.
L’utilisation du graphique de connaissances s’étend au-delà des panneaux SERP pour améliorer la recherche traditionnelle. Les documents citent également la «boîte à suicide d’auto-assistance», mettant en évidence l’importance critique de la configuration précise et le travail approfondi en déterminant les bonnes «courbes» et «seuils».
Le développement de Google, selon les documents, est motivé par les besoins des utilisateurs. Google identifie et débogue les problèmes et intègre de nouvelles informations pour améliorer le classement. Les exemples incluent:
- Ajustement des signaux pour le biais de position de liaison.
- Développer des signaux pour lutter contre les fermes de contenu.
- Innover pour garantir des résultats de qualité pour les requêtes sensibles comme «l’Holocauste s’est produit», tout en considérant la diversité des résultats nuancés.
LLMS et l’avenir de la recherche Google
Google «repense sa pile de recherche à partir de zéro», les LLM jouent un rôle plus important. Les LLM peuvent améliorer «l’interprétation des requêtes» et «la présentation résumée des résultats».
Dans une exposition séparée, nous avons regardé «l’infrastructure de recherche combinée» de Google (bien que de nombreuses parties de celle-ci aient été expurgées):
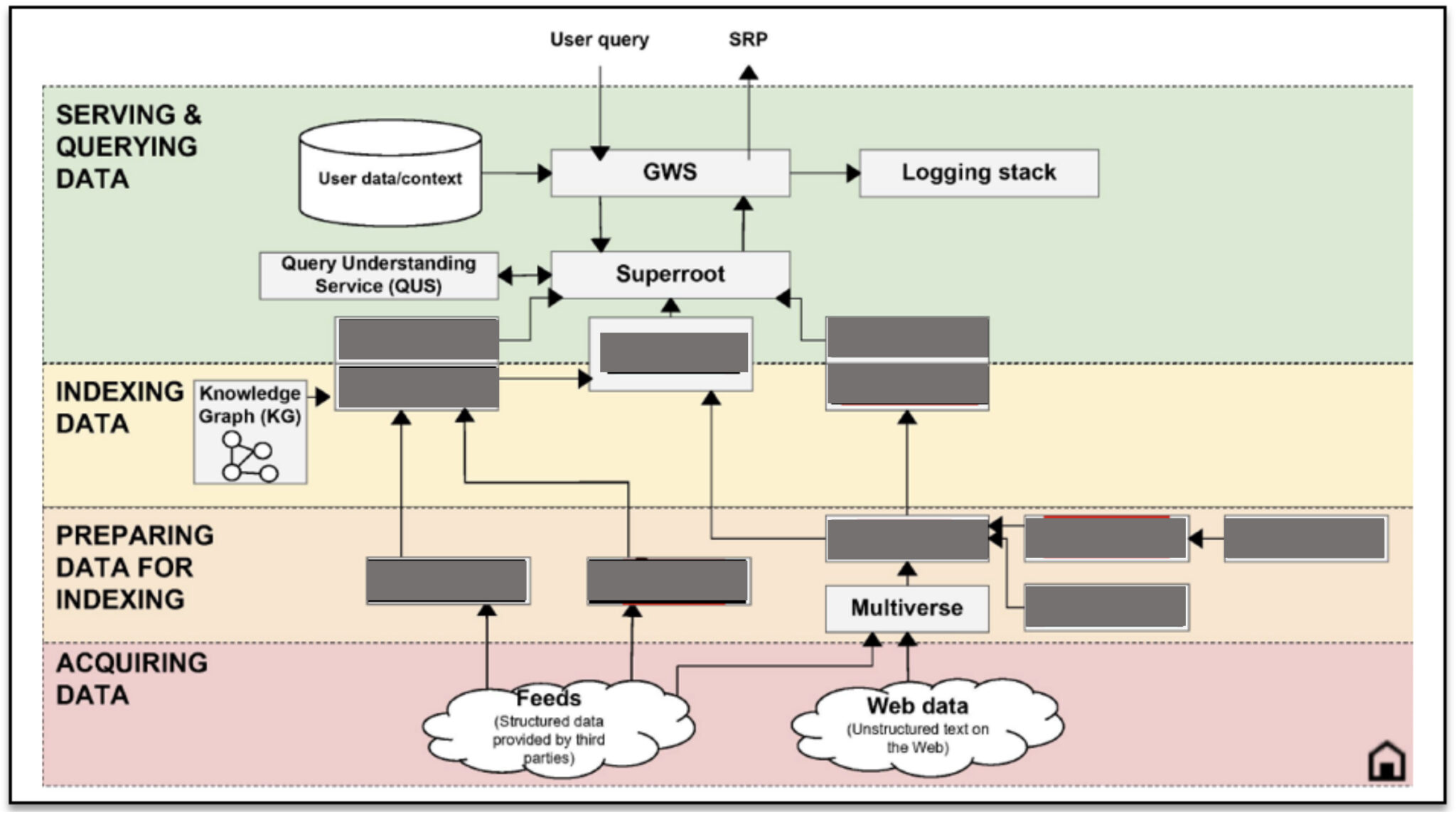
Google explore comment les LLM peuvent réinventer le classement, la récupération et l’affichage SERP. Une considération clé est le coût de calcul de l’utilisation des LLM.
Alors que les premiers modèles d’apprentissage automatique avaient besoin de beaucoup de données, Google utilise désormais «de moins en moins», parfois seulement 90 ou 60 jours. Règle de Google: utilisez les données qui servent le mieux les utilisateurs.
Tu es plus profond. Ce n’est pas la première fois que nous avons un aperçu intérieur du fonctionnement du classement de recherche Google, grâce à l’essai DOJ. Voir plus dans ces articles:
- 7 Documents de classement de recherche Google incontournable dans les expositions d’essai antitrust
- Comment fonctionne la recherche et le classement Google, selon Pandu Nayak de Google
Les expositions du procès du DOJ. États-Unis et demandeur States c. Google LLC [2020] – Remèdes entendant les expositions:
- 31 janvier 2025 Appel avec Panda Nayak (PDF)
- 18 février 2025 Appel avec HJ Kim (PDF)

