

Pensez à la façon dont les gens posent des questions sur les lunettes de soleil.
Dans l’ancien modèle de recherche, quelqu’un interroge les «meilleures lunettes de soleil intelligentes» et analyse les liens dans un SERP.
Dans le nouveau modèle, ils demandent: «Quel est le problème avec les méta-rayons?» et obtenir une réponse synthétisée avec des spécifications, des cas d’utilisation et des avis – souvent sans voir une seule page Web, y compris le SERP.
Ce changement définit la nouvelle frontière: votre contenu n’a pas à se classer. Il doit être récupéré, compriset assemblé dans une réponse.
Le jeu était autrefois: Écrivez une page, attendez que Google / Bing le rampe, espérons que vos mots clés correspondent à la requête et priez que personne n’ait acheté la fente publicitaire au-dessus de vous. Mais ce modèle s’effondre tranquillement.
Les systèmes d’IA génératifs n’ont pas besoin que votre page apparaisse dans une liste – ils en ont juste besoin pour être structurés, interprétables et disponibles quand il est temps de répondre.
Ceci est la nouvelle pile de recherche. Non construit sur des liens, des pages ou des classements – mais sur des vecteurs, des incorporations, de la fusion de classement et des LLM pour la raison au lieu du rang.
Vous ne vous contentez plus d’optimiser la page. Vous optimisez comment votre contenu est éclaté, score sémantiquement et cousu ensemble.
Et une fois que vous comprenez comment ce pipeline fonctionne généralement, l’ancien livre de jeu SEO commence à paraître pittoresque. (Ce sont des pipelines simplifiés.)

Rencontrez la nouvelle pile de recherche
Sous le capot de chaque système d’IA moderne de récupération, se trouve une pile invisible pour les utilisateurs – et radicalement différente de la façon dont nous sommes arrivés ici.
Incorporer
Chaque phrase, paragraphe ou document est converti en vecteur – un instantané de haute dimension de sa signification.
- Cela permet aux machines de comparer les idées par proximité, pas seulement des mots clés, leur permettant de trouver du contenu pertinent qui n’utilise jamais les termes de recherche exacts.
Bases de données vectorielles (DBS vectoriel)
Ceux-ci stockent et récupèrent ces intérêts à grande vitesse. Pensez à Pinecone, Weavate, Qdrant, Faiss.
- Lorsqu’un utilisateur pose une question, il est également intégré – et la DB renvoie les morceaux correspondants les plus proches en millisecondes.
BM25
Old-school? Oui.
Toujours utile? Absolument.
BM25 classe le contenu basé sur la fréquence des mots clés et la rareté.
- C’est idéal pour la précision, surtout lorsque les utilisateurs recherchent des termes de niche ou s’attendent à des correspondances de phrases exactes.
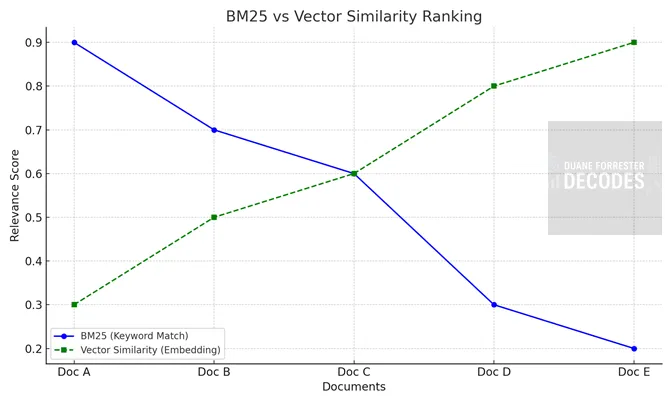
Ce graphique est une comparaison conceptuelle du comportement de classement de similitude BM25 vs vectoriel. Sur la base de données hypothétiques pour illustrer comment les deux systèmes évaluent la pertinence différemment – un chevauchement des mots clés exacts hiérarchisés, l’autre contenu sémantiquement similaire. Notez que les documents apparaissent dans l’ordre.
RRF (Fusion de rang réciproque)
Cela mélange les résultats de plusieurs méthodes de récupération (comme BM25 et la similitude vectorielle) dans une liste classée.
- Il équilibre les mots clés avec des matchs sémantiques afin qu’aucune approche ne dépasse la réponse finale.
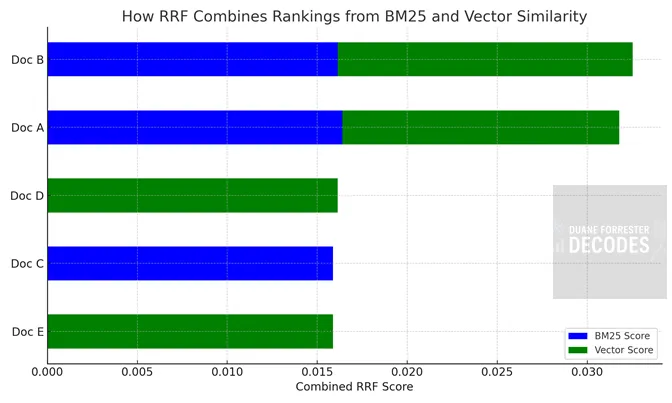
RRF combine les signaux de classement de BM25 et la similitude vectorielle en utilisant les scores de rang réciproques. Chaque barre ci-dessous montre comment la position d’un document dans différents systèmes contribue à son score RRF final – favorisant le contenu qui se classe régulièrement sur plusieurs méthodes, même si ce n’est pas le premier non non plus. Nous pouvons voir que l’ordre de document est affiné dans cette modélisation.
LLMS (grands modèles de langue)
Une fois les résultats supérieurs récupérés, le LLM génère une réponse – résumé, reformulé ou directement cité.
- Il s’agit de la couche «raisonnement». Il ne se soucie pas d’où vient le contenu – il se soucie de savoir si elle aide à répondre à la question.
Et oui, l’indexation existe toujours. Cela semble juste différent.
Il n’y a pas de rampe et d’attente qu’une page se classe. Le contenu est intégré dans une base de données vectorielle et rendu réalisable en fonction du sens, et non des métadonnées.
- Pour les données internes, c’est instantané.
- Pour le contenu Web public, des robots comme GPTBOT et Google-étendus visitent toujours des pages, mais ils indexent la signification sémantique, pas la construction pour les SERP.
Pourquoi cette pile gagne (pour les bons emplois)
Ce nouveau modèle ne tue pas la recherche traditionnelle. Mais il le saute – en particulier pour les tâches, les moteurs de recherche traditionnels n’ont jamais bien géré.
- Vous recherchez vos documents internes? Cela gagne.
- Résumer les transcriptions juridiques? Pas de concours.
- Vous trouverez des extraits pertinents dans 10 PDF? Jeu terminé.
Voici ce à quoi il excelle:
- Latence: Les DB vectoriels récupèrent en millisecondes. Pas de rampe. Pas de retard.
- Précision: Les intégres correspondent à la signification, pas seulement aux mots clés.
- Contrôle: Vous définissez le corpus – pas de pages aléatoires, pas de spam de référencement.
- Sécurité de la marque: Pas d’annonces. Aucun concurrent détournant vos résultats.
C’est pourquoi la recherche d’entreprise, le support client et les systèmes de connaissances internes sautent en premier. Et maintenant, nous voyons une recherche générale se diriger de cette façon à grande échelle.
Comment les graphiques de connaissances améliorent la pile
Les vecteurs sont puissants, mais flous. Ils se rapprochent du sens mais manquent les relations «qui, quoi, quand» les humains tiennent pour acquis.
C’est là que les graphiques de connaissances entrent en jeu.
Ils définissent les relations entre les entités (comme une personne, un produit ou une marque) afin que le système puisse désambiguier et raisonner. Parlons-nous d’Apple l’entreprise ou les fruits? «Il» fait-il référence à l’objet ou au client?
Utilisé ensemble:
- Le Vector DB trouve un contenu pertinent.
- Le graphique de connaissance clarifie les connexions.
- Le LLM explique tout en langue naturelle.
Vous n’avez pas à choisir un graphique de connaissances ni la nouvelle pile de recherche. Les meilleurs systèmes d’IA génératifs utilisent les deux, ensemble.
Guide de champ tactique: optimisation pour la récupération alimentée par AI
Tout d’abord, appuyons sur un rafraîchissement rapide sur ce à quoi nous sommes tous habitués – ce qu’il faut pour classer pour la recherche traditionnelle.
Une chose clé ici – ce n’est pas exhaustif, cet aperçu. C’est simplement ici pour définir le contraste de ce qui suit. Même la recherche traditionnelle est un complexe Hella (je devrais savoir, après avoir travaillé à l’intérieur du moteur de recherche Bing), mais cela semble assez docile quand vous voyez ce qui va venir!
Pour se classer dans la recherche traditionnelle, vous vous concentrez généralement sur des choses comme ceci:
- Vous avez besoin de pages de randable, de contenu aligné par mot-clé, de balises de titre optimisées, de vitesses de charge rapide, de backlinks provenant de sources réputées, de données structurées et de liaison interne solide.
- Saupoudrer de EEAT (expérience, expertise, autorité, fiabilité), une convivialité et des signaux d’engagement des utilisateurs, et vous êtes dans le jeu.
C’est un mélange d’hygiène technique, de pertinence de contenu et de réputation – et toujours mesurée en partie par la façon dont les autres sites vous indiquent.
Maintenant, pour la partie qui vous importe: comment vous apparaissez-vous dans cette nouvelle pile générative-AI?
Vous trouverez ci-dessous les mouvements réels, Tactical que chaque propriétaire de contenu devrait faire s’ils veulent des systèmes d’IA génératifs comme Chatgpt, Gemini, Copilot, Claude et Perplexity de retirer de leur site.
1. Structure pour la chasse et la récupération sémantique
Brisez votre contenu en blocs récupérables.
Utilisez le HTML sémantique (
, , etc.) pour définir clairement les sections et isoler les idées.
Ajouter les FAQ et la mise en forme modulaire.
Ceci est la couche de mise en page – ce que les LLMS voient d’abord lors de la rupture de votre contenu en morceaux.
2. Prioriser la clarté sur l’intelligence
Écrivez comme si vous vouliez être compris, pas admiré.
Évitez le jargon, les métaphores et les intros duveteux.
Savourez des réponses spécifiques, directes et simples qui s’alignent sur la façon dont les utilisateurs expliquent les questions.
Cela améliore la qualité du match sémantique lors de la récupération.
3. Faites votre site Ai-Crawlable
Si GPTBOT, Google-étendu ou CCBOT ne peut pas accéder à votre site, vous n’existez pas.
Évitez le contenu rendu javascripFAQPage, Article, HowTo) pour guider les robots et clarifier le type de contenu.
4. Établir des signaux de confiance et d’autorité
Biais LLMS vers des sources fiables.
Cela signifie des règles, des dates de publication, des pages de contact, des citations sortantes et des bios des auteurs structurés.
Les pages avec ces marqueurs sont beaucoup plus susceptibles d’être surfacées dans des réponses génératives de l’IA.
5. Construisez des relations internes comme un graphique de connaissances
Lier les pages liées et définir les relations sur votre site.
Utilisez des modèles Hub and Spoke, des glossaires et des liens contextuels pour renforcer la façon dont les concepts se connectent.
Cela construit une structure de type graphique qui améliore la cohérence sémantique et la récupération à l’échelle du site.
6. Couvrir les sujets profondément et modulairement
Répondez à chaque angle, pas seulement la question principale.
Découvrez le contenu en «quoi», «pourquoi», «comment», «vs» et «quand».
Ajoutez TL; DRS, résumés, listes de contrôle et tables.
Cela rend votre contenu plus polyvalent pour le résumé et la synthèse.
7. Optimiser la confiance de la récupération
Les LLM pèsent à quel point ils sont confiants dans ce que vous avez dit avant de l’utiliser.
Utilisez un langage clair et déclaratif.
Évitez les phrases de couverture comme «pourrait», «peut-être» ou «certains croient», sauf si vous avez absolument besoin.
Plus votre contenu sonne confiant, plus il est susceptible d’être fait surface.
8. Ajouter la redondance par le biais de reformulations
Dites la même chose plus d’une fois, de différentes manières.
Utilisez la diversité de phrasé pour étendre votre surface sur différentes requêtes utilisateur.
Les moteurs de récupération correspondent à la signification, mais plusieurs libellés augmentent votre empreinte vectorielle et votre couverture de rappel.
9. Créer des paragraphes adaptés à l’intégration
Écrivez des paragraphes propres et ciblés qui mappent à des idées uniques.
Chaque paragraphe doit être autonome, éviter plusieurs sujets et utiliser une structure de phrase simple.
Cela rend votre contenu plus facile à intégrer, récupérer et synthétiser avec précision.
10. Inclure le contexte des entités latentes
Énoncer des entités importantes – même lorsqu’elles semblent évidentes.
Ne dites pas simplement «le dernier modèle». Dites «Openai’s GPT-4 Model».
Plus vos références d’entité sont claires, plus votre contenu fonctionne dans des systèmes à l’aide de superpositions de graphiques de connaissances ou d’outils de désambiguation.
11. Utilisez des ancres contextuelles proches de points clés
Soutenez directement vos idées principales – pas à trois paragraphes.
Lorsque vous faites une réclamation, mettez des exemples, des statistiques ou des analogies à proximité.
Cela améliore la cohérence au niveau des morceaux et permet aux LLM de raisonner plus facilement sur votre contenu en toute confiance.
12. Publier des extraits structurés pour les robots génératifs de l’IA
Donnez à Crawlers quelque chose de propre à copier.
Utilisez des puces, des résumés de réponses ou de courtes sections «à emporter clés» pour faire surface d’informations de grande valeur.
Cela augmente vos chances d’être utilisé dans des outils d’IA génératifs basés sur l’extrait comme Perplexity ou You.com.
13. Nourrir l’espace vectoriel avec un contenu périphérique
Construisez un quartier dense d’idées connexes.
Publier un contenu à l’appui comme les glossaires, les définitions, les pages de comparaison et les études de cas. Les relier ensemble.
Une carte de sujet étroitement en grappe améliore le rappel de vecteur et stimule la visibilité de votre contenu de pilier.
Bonus: vérifiez l’inclusion
Vous voulez savoir si cela fonctionne? Demandez à la perplexité ou à la chatte avec la navigation pour répondre à une question que votre contenu devrait couvrir.
Si cela ne se présente pas, vous avez du travail à faire. Structure mieux. Clarifier plus. Puis demandez à nouveau.
Réflexion finale: votre contenu est maintenant une infrastructure
Votre site Web n’est plus la destination. C’est la matière première.
Dans un monde d’IA génératif, le mieux que vous puissiez espérer est d’être utilisé – cité, cité ou synthétisé dans une réponse que quelqu’un entend, lit ou agit.
Cela va être de plus en plus important à mesure que les nouveaux points d’accès aux consommateurs deviennent plus courants – pensez à des choses comme les lunettes de méta-rayons de nouvelle génération, à la fois comme un sujet qui est recherché et comme exemple de l’endroit où la recherche se produira bientôt.
Les pages comptent toujours. Mais de plus en plus, ce ne sont que des échafaudages.
Si vous voulez gagner, arrêtez de vous obséder au cours des classements. Commencez à penser comme une source. Il ne s’agit plus de visites, il s’agit d’être inclus.
Cet article a été initialement publié sur Duane Forrester Decodes sur Sublack (comme recherche sans page Web) et est republié avec permission.
Ajouter les FAQ et la mise en forme modulaire.
Ceci est la couche de mise en page – ce que les LLMS voient d’abord lors de la rupture de votre contenu en morceaux.
2. Prioriser la clarté sur l’intelligence
Écrivez comme si vous vouliez être compris, pas admiré.
Évitez le jargon, les métaphores et les intros duveteux.
Savourez des réponses spécifiques, directes et simples qui s’alignent sur la façon dont les utilisateurs expliquent les questions.
Cela améliore la qualité du match sémantique lors de la récupération.
3. Faites votre site Ai-Crawlable
Si GPTBOT, Google-étendu ou CCBOT ne peut pas accéder à votre site, vous n’existez pas.
Évitez le contenu rendu javascripFAQPage, Article, HowTo) pour guider les robots et clarifier le type de contenu.
4. Établir des signaux de confiance et d’autorité
Biais LLMS vers des sources fiables.
Cela signifie des règles, des dates de publication, des pages de contact, des citations sortantes et des bios des auteurs structurés.
Les pages avec ces marqueurs sont beaucoup plus susceptibles d’être surfacées dans des réponses génératives de l’IA.
5. Construisez des relations internes comme un graphique de connaissances
Lier les pages liées et définir les relations sur votre site.
Utilisez des modèles Hub and Spoke, des glossaires et des liens contextuels pour renforcer la façon dont les concepts se connectent.
Cela construit une structure de type graphique qui améliore la cohérence sémantique et la récupération à l’échelle du site.
6. Couvrir les sujets profondément et modulairement
Répondez à chaque angle, pas seulement la question principale.
Découvrez le contenu en «quoi», «pourquoi», «comment», «vs» et «quand».
Ajoutez TL; DRS, résumés, listes de contrôle et tables.
Cela rend votre contenu plus polyvalent pour le résumé et la synthèse.
7. Optimiser la confiance de la récupération
Les LLM pèsent à quel point ils sont confiants dans ce que vous avez dit avant de l’utiliser.
Utilisez un langage clair et déclaratif.
Évitez les phrases de couverture comme «pourrait», «peut-être» ou «certains croient», sauf si vous avez absolument besoin.
Plus votre contenu sonne confiant, plus il est susceptible d’être fait surface.
8. Ajouter la redondance par le biais de reformulations
Dites la même chose plus d’une fois, de différentes manières.
Utilisez la diversité de phrasé pour étendre votre surface sur différentes requêtes utilisateur.
Les moteurs de récupération correspondent à la signification, mais plusieurs libellés augmentent votre empreinte vectorielle et votre couverture de rappel.
9. Créer des paragraphes adaptés à l’intégration
Écrivez des paragraphes propres et ciblés qui mappent à des idées uniques.
Chaque paragraphe doit être autonome, éviter plusieurs sujets et utiliser une structure de phrase simple.
Cela rend votre contenu plus facile à intégrer, récupérer et synthétiser avec précision.
10. Inclure le contexte des entités latentes
Énoncer des entités importantes – même lorsqu’elles semblent évidentes.
Ne dites pas simplement «le dernier modèle». Dites «Openai’s GPT-4 Model».
Plus vos références d’entité sont claires, plus votre contenu fonctionne dans des systèmes à l’aide de superpositions de graphiques de connaissances ou d’outils de désambiguation.
11. Utilisez des ancres contextuelles proches de points clés
Soutenez directement vos idées principales – pas à trois paragraphes.
Lorsque vous faites une réclamation, mettez des exemples, des statistiques ou des analogies à proximité.
Cela améliore la cohérence au niveau des morceaux et permet aux LLM de raisonner plus facilement sur votre contenu en toute confiance.
12. Publier des extraits structurés pour les robots génératifs de l’IA
Donnez à Crawlers quelque chose de propre à copier.
Utilisez des puces, des résumés de réponses ou de courtes sections «à emporter clés» pour faire surface d’informations de grande valeur.
Cela augmente vos chances d’être utilisé dans des outils d’IA génératifs basés sur l’extrait comme Perplexity ou You.com.
13. Nourrir l’espace vectoriel avec un contenu périphérique
Construisez un quartier dense d’idées connexes.
Publier un contenu à l’appui comme les glossaires, les définitions, les pages de comparaison et les études de cas. Les relier ensemble.
Une carte de sujet étroitement en grappe améliore le rappel de vecteur et stimule la visibilité de votre contenu de pilier.
Bonus: vérifiez l’inclusion
Vous voulez savoir si cela fonctionne? Demandez à la perplexité ou à la chatte avec la navigation pour répondre à une question que votre contenu devrait couvrir.
Si cela ne se présente pas, vous avez du travail à faire. Structure mieux. Clarifier plus. Puis demandez à nouveau.
Réflexion finale: votre contenu est maintenant une infrastructure
Votre site Web n’est plus la destination. C’est la matière première.
Dans un monde d’IA génératif, le mieux que vous puissiez espérer est d’être utilisé – cité, cité ou synthétisé dans une réponse que quelqu’un entend, lit ou agit.
Cela va être de plus en plus important à mesure que les nouveaux points d’accès aux consommateurs deviennent plus courants – pensez à des choses comme les lunettes de méta-rayons de nouvelle génération, à la fois comme un sujet qui est recherché et comme exemple de l’endroit où la recherche se produira bientôt.
Les pages comptent toujours. Mais de plus en plus, ce ne sont que des échafaudages.
Si vous voulez gagner, arrêtez de vous obséder au cours des classements. Commencez à penser comme une source. Il ne s’agit plus de visites, il s’agit d’être inclus.
Cet article a été initialement publié sur Duane Forrester Decodes sur Sublack (comme recherche sans page Web) et est republié avec permission.